Store opdateringer og forbedringer af MyHeritage DNA-matchning

Vi er glade for at kunne annoncere store opdateringer og forbedringer af DNA-matching som er klar for alle vores brugere fra denne uge. Enhver der har taget en MyHeritage DNA-test, og enhver der har uploadet deres DNA-data fra en anden tjeneste, vil nu modtage mere præcise DNA-matches; flere matches (ca. 10x flere); færre falske positiver; mere specifikke og præcise forholdsestimater; og indikationer på lavere tillid til visse DNA-matches for at hjælpe med at fokusere din forskningsindsats. Vi tilføjede også den længe anmodet Chrome-browserfunktion, der er beskrevet nedenfor.
Vores videnskabsteam har arbejdet i mange måneder på disse forbedringer. Det tog meget tid og kræfter, fordi vi ønskede at perfektionere videnskaben og give vores brugere optimale resultater.
Hvad er DNA-matchning?
MyHeritage DNA har i øjeblikket mere end én million mennesker i DNA-databasen. 1,075 millioner for at være helt præcis. DNA-matchning sammenligner DNA-tests i MyHeritage-databasen med hinanden for at finde pårørende, dvs. personer der deler DNA-segmenter med hinanden, og hjælper med at forklare hvordan disse personer er relaterede. Tilstedeværelsen af delte DNA-segmenter mellem to personer kan indikere at de er beslægtet, hvilket betyder at de delte segmenter blev arvet fra en fælles forfader. Hvis de delte segmenter er talrige og store, er en en forbindelse mere sikkert. På den anden side, hvis de delte segmenter er små i antal og størrelse, kan der også være tale om en tilfældighed, der ikke tyder på en forbindelse overhovedet. Når en match er rapporteret der overhovedet ikke er en slægtning, er der tale om en falsk positiv.
Hvis du har taget en MyHeritage DNA-test og modtaget resultaterne, eller uploadet dine DNA-data til MyHeritage, så har du modtaget en liste over dine DNA-matches. Matchene opdateres dagligt, og brugere får besked via en ugentlig e-mail om de bedste nye matches de har modtaget den pågældende uge. Med “bedste”, menes de matches der har den største mængde af delt DNA, der angiver et tættere forhold. Listen over DNA-matches viser personer der deler DNA-segmenter med dig, mængden og procentdelen af DNA I deler, antallet af DNA-segmenter I deler, og størrelsen af det største delte segment. MyHeritage estimerer også forholdet ved at analysere antallet og størrelsen af de delte DNA-segmenter i hver match, og sammenligne dem med en referencepulje af hundredtusinder af andre matches med kendte relationer i henhold til familietræer der er blevet bekræftet af DNA. DNA-match Tjekker siden tilbyder ledetråde som du kan følge op med, for at spore din slægt tilbage til jeres fælles forfader.
Fra og med denne uge, vil brugere der har modtaget DNA Matches før, se ændrede og forbedrede matches som følge af disse forbedringer. Det betyder, at mange nye matches vil vises. Nogle matches der eksisterede før, der var falske positive, vil forsvinde. Mange matches vil have deres parametre ændret (f.eks. mængden af delt DNA) til mere nøjagtige værdier. Brugere der ikke har modtaget matches endnu, vil modtage de højere kvalitetsmatches fra dag 1.
Hvordan virker DNA Matching?

Skematisk præsentation af processen der producerer DNA-matches.
Lad os starte med et hurtigt overblik over hvordan DNA-matchning fungerer. Derefter vil vi dykke ind i de forbedringer vi har lavet i de forskellige stadier af processen.
Processen begynder, når du tager en DNA-test, og sender din prøve til vores laboratorium. I laboratoriet læser vi dit DNA, og producerer en datafil med oplysningerne. Vi læser ikke alle dele af dit DNA som svarer til omkring 3 milliarder punker. Dette er en dyr metode kaldet Hel–genom-sekventering, som i øjeblikket er forbeholdt specifikke kliniske og forskningsapplikationer. I stedet fokuserer vi på at læse ca. 700.000 steder i dit DNA, der er kendt for at variere mellem individer, der kaldes enkeltnukleotidpolymorfi (SNPs, udtalt “snips”). Denne metode kaldes genotypebestemmelse, og den producerer en datafil, som viser hver SNP vi læser, dens position i dit DNA, og de to genotyper vi fandt der (dvs. A, T, G eller C du arvede fra hver af dine forældre). Hvis du uploader DNA-data fra en anden tjeneste, modtager vi datafilen med de samme oplysninger.
Dernæst bruger vi imputation til at udlede SNP’erne, som vi ikke læste. Tænk på at imputere DNA som at læse en sætning med nogle af bogstaverne der mangler – der er en god chance for at du kan udlede de manglende bogstaver fra konteksten. Ikke alle DNA-udbydere læser de samme SNP’er. For at finde DNA-matches for personer der har brugt forskellige DNA-udbydere, er det vigtigt at udlede SNP’erne som ikke blev læst før sammenligningen af resultaterne. Nogle mennesker stiller spørgsmålstegn ved nøjagtigheden af imputation. Vi fandt imidlertid, at denne metode er meget nøjagtig når den anvendes korrekt, og i nogle tilfælde er brugen uundgåelig.
Efter imputation kommer “phasing”. I hvert par af kromosomer, får hver person et kromosom fra deres mor og et fra deres far. Genotypeteknologien, der læser din DNA-prøve, bestemmer hvilke genotyper du arver fra dine forældre for hver hver SNP, men den fortæller os ikke hvilke grupper af varianter der blev arveret fra samme forælder. Phasing hjælper os med at sortere dette. Det klynger alle varianter arvet fra en af dine forældre i en spand, og varianterne arvet fra den anden forælder i en anden spand.
Det næste skridt er at udføre den faktiske matchning, og sammenligne alle DNA-tests i databasen som ikke har fravalgt matchning, med hinanden. Vi gør dette på et meget skalerbart system kaldet Hadoop, som gør det muligt for os at udføre massiv distribueret behandling meget effektivt. Matchningen identificerer de delte segmenter mellem hvert par test, hvorfra forholdet mellem de to individer (hvis der er nogen) kan udledes. Tilstødende delte segmenter bliver så “syet”, hvis de betragtes som sammenhængende.
Endelig bruger vi avancerede statistiske algoritmer, der kaldes klassifikatorer, til at gennemgå DNA-matches og afvise falske positive, for at bestemme tillidsniveauet for de matches der ikke blev afvist, og for at foreslå typen af forhold for hver match. Sådan skaber vi din liste over DNA-matches.
Hvordan har vi forbedret DNA Matchning?
Vi har forbedret nøjagtigheden af vores imputering betydeligt ved at øge antallet af referencegenomer med mere end ti. Ligesom at læse 10 gange så mange bøger ville gøre det muligt for en person at udlede manglende bogstaver fra flere sætninger mere præcist, øgede vores referencegenompanel klart vores evne til at imputere SNP’er som vi ikke læste, mere præcist.
Vi rettede op på “phasing”. Den tidligere behandling af DNA Matches havde lejlighedsvise fejl i fasetrinnet. Disse fejl har givet nogle falske positiver, hvor vi tidligere har estimeret delte segmenter af meget fjernt slægtninge. Det skabte også problemer, hvor vi tidligere havde estimeret delte segmenter af nære slægtninge. Vi bruger nu en bedre algoritme, der retter disse fasefejl.
I matchningsfasen har vi rekalibreret tærsklen for genotypefejl. Den teknologi, der læser din DNA-prøve, tager lejlighedsvist fejl. Disse kaldes genotypingsfejl. Hvis der opstår en genotypefejl i midten af hvad der skulle være et delt segment mellem DNA-matches, ligner det ikke det samme segment, og det kan opdeles i to matchende segmenter, der er mindre. Vi rekalibrerede tærsklen for hvornår vi ignorerer små fejlmatcher mellem ellers matchende segmenter, og i stedet behandler de delte segmenter som identiske til trods for små stykker der ikke stemmer overens. Denne metode kompenserer for uundgåelige genotypefejl. Hvis vi ignorerer uoverensstemmende sektioner der er for store, vil vi ved et uheld antage, at et segment deles, når det egentlig ikke gør det; hvis vi ikke ignorerer uoverensstemmende sektioner der er resultatet af genotypefejl, vil vi sandsynligvis gå glip af ægte DNA-matches. Den nye kalibrering er blevet skærpet i forhold end den foregående, hvilket betyder at færre falske positiver vil slippe igennem.
Flere fjerne matches er nu tilladt. Efter at have øget nøjagtigheden af matchene og kalibrering af ovenstående parametre, følte vi os trygge ved at de mere fjerne matches kunne blive præsenteret for dig. Tidligere var det minimale segment for delt DNA for en match 12 cM, og nu er minimummet 8 cM. Dette, sammen med de andre forbedringer, betyder at vores brugere nu vil modtage ti gange så mange DNA Matches i forhold til før.
Disse matches vil vises automatisk for alle der allerede har foretaget en MyHeritage DNA-test, eller enhver der allerede har uploadet deres DNA til MyHeritage, og for alle der gør det i fremtiden.
Bedre hæftning af tilstødende segmenter. Ud over at kompensere for genotypefejl i segmenter, er det nødvendigt at kompensere for de resterende fasefejl mellem segmenter. For eksempel forventes det, med undtagelse af kønschromosomet, at en mor og datter har 22 matchende segmenter i en autosomal DNA-test: Et helt kromosom fra hver af datterens kromosompar blev arvet fra hendes mor, og derfor burde hver af de 22 autosomale kromosomer ligne et enkelt, langt matchende segment. På grund af fasefejl, er små dele af kromosomet arvet fra moderen, nogle gange byttet ud med de parallelle sektioner der er arvet fra faderen. Dette skyldes tekniske fejl, ikke biologiske processer. Vi overvinder disse fejl ved at øge størrelsen af de huller vi syr, mens vi kalibrerer dette nøjagtigt for at undgå at introducere nye fejl.
Det sidste trin i DNA-matchning er at bortfiltrere falske positiver og estimere det specifikke forhold mellem to personer med delte DNA-segmenter. Fordi mange af os er efterkommere af de samme meget gamle forfædre, har vi ofte små delte DNA-segmenter med enkeltpersoner vi ikke rigtigt ville føle er familie. Vi søgte en metode til at bortfiltrere sådanne matches der frustrerer genealoger. Til dette formål måler vi falske positiver internt ved at se på trios – disse er sæt med barn, mor og far, som alle blev testet med MyHeritage DNA-sæt og har modtaget resultater der bekræftede, at forholdet mellem forældrene og barnet er korrekt. Enhver match som et barn har med en anden person som hverken matcher faderen eller moderen, mistænkes for at være en falsk positiv og kaldes en child-only match. Vi måler procentdelen af child-only matches blandt alle matches, der returneres til børn i alle kendte trioer på MyHeritage, og denne figur kaldes procentdelen af mistænkte falske positiver, der er angivet ved child-only matches. Vi formåede at bringe dette tal ned til 16-20 procent, hvilket er et godt resultat, som vi ved, svarer til eller er bedre end alle andre DNA-tjenester. Vores forbedrede klassificeringsalgoritmer har lykkedes med at bringe vores falske positiver til det laveste niveau nogensinde.
Men vi stoppede ikke med det. Vi ønskede at oprette en metode, der giver dig mulighed for at fokusere din slægtsforskning på den mest effektive måde. Til dette, anvendte vi vores statistiske algoritmer til at kategorisere matchene i: høj, medium og lav tillidsmatches. Matches med lav eller medium tillid er mærket således på hjemmesiden. Dette er DNA-matches der bør behandles med skepsis, fordi de risikerer at være falske positive. Sådanne matches har typisk meget få, meget små delte DNA-segmenter. Disse indikationer giver dig mulighed for at udnytte din tid bedst muligt. Følg først op på høje tillidsmatches, og hvis du så er i humør til en udfordring, gå igennem lavere og medium tillidsmatches for skjulte skatte. Bemærk, at små og medium tillidsmatches er ekskluderet fra de ugentlige email-notifikationer på nye matches.
De nye klassifikatorer er så gode, at procentdelen af child-only matches, der ikke er markeret som lav eller medium tillid, nu er mindre end 5%. Med andre ord, når du gennemgår en DNA-match på MyHeritage der ikke er markeret som lav eller medium tillid, kan du næsten være sikker på, at du ikke spilder din tid på en falsk positiv. Hvis matchen du vurderer, anslås at være en grandfætter eller tættere, er der så meget delt DNA, at du kan være sikker på det ikke er en falsk positiv.
Nøjagtigheden ved at estimere et forhold af en DNA-match måles ved hjælp af to parametre kaldet recall og præcision. Perfekt nøjagtighed betyder både at fortælle en bruger det korrekte forhold til en DNA-match hver gang (recall), mens at kun det forhold og ikke et bredere udvalg af mulige relationer bliver foreslået (præcision). For eksempel, hvis to personer rent faktisk er søskende, vil en perfekt algoritme foreslå at de er søskende og kun antyde at de er søskende; den vil ikke skønne at de er enten søskende eller fætre. (Denne teoretiske perfekte algoritme er dog ikke biologisk muligt på grund af DNA-arvens art). MyHeritage kan nu foreslå DNA-matches korrekte forhold 93% af tiden for fjerne familiemedlemmer som fætre i 4. eller 5. led, hvilket er utroligt vanskeligt at gøre. For nære slægtninge er nøjagtigheden meget højere og er tæt på 100%. Samtidig vil vi kun foreslå 2 eller 3 mulige relationer til DNA-matches som er grandfætre/kusiner eller tættere. For fjerne fætre/kusiner vil vi vise et gennemsnit på op til 5 mulige relationer (f.eks. fætter i 2. led en gang fjernet og fætter i 3. led) – et relativt snævert område alt taget i betragtning. Præcisionen og recall af MyHeritages forholdsestimater er nu meget bedre end tidligere.
Vi validerede den høje kvalitet af vores nye DNA-matchning-algoritme, ved at sammenligne nye DNA-match lister til dem der produceres af andre DNA-virksomheder, og resultaterne er meget ens.
Visse særlige endogamiske populationer, som Ashkenaziske jøder, udgør en unik DNA-matchende udfordring. Fordi disse populationer oplevede en betydelig mængde af blandede ægteskaber, har ikke-genealogrelaterede personer inden for disse populationer mere delt DNA end det ellers ville forventes for ikke-slægtninge. MyHeritage trænede en yderligere klassifikationsalgoritme ved hjælp af maskinindlæring til at klassificere Ashkenaziske relationer med højere opløsning end nogen anden DNA-tjeneste. Vi brugte denne klassifikator til at give bedre afvisning af falske positiver for Ashkenaziske jøder, og bringe dem til det samme niveau af falske positive som den generelle befolkning.
Hvad betyder disse forbedringer for MyHeritage DNA-brugere?
Nu får du:
- Mere nøjagtige DNA-matches
- Ca. 10 gange så mange DNA-matches
- Mere specifikke og præcise forholdsestimater
- Indikationer af DNA-match tillidsniveauer til at hjælpe med at fokusere din forskningsindsats
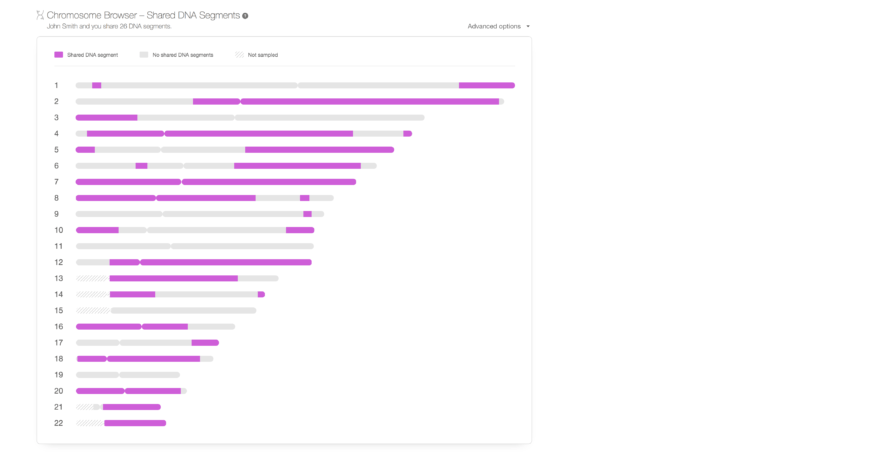
Kromosombrowser
Sammen med forbedringer i nøjagtighed, har vi også tilføjet nye funktioner til forbedring af brugen af DNA-matches. Den første, som er blevet meget efterspurgt, er en kromosombrowser til delte DNA-matches. Det er blevet tilføjet til DNA Match Tjekker-siden.

En kromosombrowser er en skematisk repræsentation af en persons kromosomer, hvor DNA-segmenter kan visualiseres. Mange af vores brugere har anmodet om en kromosombrowser, og vi ved at dette er et vigtigt værktøj for slægtsforskere. Derfor lovede vi at vi ville udvikle en, og vi holdt vores løfte. Den nye kromosombrowser hos MyHeritage er en indledende udgivelse, som vil blive forbedret yderligere snart, og beregnet til visning af delte DNA-segmenter for alle DNA-matches. Det er en gratis funktion, der kan bruges af alle brugere på MyHeritage der har taget DNA-testen eller uploadet DNA-data. Det viser de delte segmenter mellem dig og en DNA-match i lilla. Når du svæver musen over et delt segment, kan du se den genomiske position af det delte segment, størrelsen på segmentet og antallet af SNP’er der er. Grå segmenter deles ikke med DNA-matchen, og krydsede sektioner blev ikke analyseret på grund af manglen på SNP’er i disse regioner. Bemærk at selvom vi aldrig nogensinde ville tillade en anden bruger at downloade dine rå DNA-data, at hvis en anden bruger har et delt segment med dig og kan se dens detaljer (position og størrelse) og derefter gennemgå det pågældende segments oplysninger om hans eller hendes eget DNA, kan den anden bruger udlede de genotyper som du har i dit DNA i det pågældende segment. Brugere der foretrækker at forhindre andre brugere der matcher deres DNA fra at se detaljerne i delte segmenter, kan fravælge denne funktion ved at bruge en ny privatlivsindstilling, som vi tilføjede til dette formål.
Kromosombrowseren inkluderer også evnen til at downloade data om delte segmenter. Dette er tilgængeligt via menuen “Avancerede indstillinger” øverst til højre i kromosombrowseren. Avancerede brugere kan bruge denne mulighed til at downloade oplysningerne om de delte segmenter og derefter bruge dem til visning i andre værktøjer eller kromosombrowsere. Flere funktioner vil snart komme ud, som f.eks. muligheden for at se tre eller flere DNA-matches delte segmenter samtidigt i Kromosombrowseren. At se de delte segmenter af flere DNA-matches samtidig, hjælper dig med at spore og identificere den delte forfader segmentet er nedarvet fra, til alle de DNA-matches der deler det, og opdage hvordan I er relateret. Vi planlægger også snart at tilføje muligheden for at udskrive de delte segmenter der vises af kromosombrowseren.
Med lidt øvelse, er vi sikre på at vores brugere vil kunne bruge den nye kromosombrowserfunktion til at begynde at identificere specifikke segmenter i deres DNA og forfaderen de stammer fra, få bedre indsigt i deres DNA-match, og bedre forstå forholdet mellem disse DNA-matches.
Ansigtsløftning og nemmere navigation
Som en del af denne opdatering, lavede vi små ændringer af brugergrænsefladen af DNA-matches, for at være mere konsistente med de andre DNA-skærme. De fleste af disse ændringer er små og næppe mærkbare, såsom knapper på listen over DNA-matches er lilla i stedet for orange. En anden meningsfuld forbedring er, at DNA-match-listesiden nu dækker detaljerne i DNA-sættet du ser øverst, så når du ruller ned gennem listen vil du aldrig miste overblikket over hvilke matches du kigger på.

Mere arbejde i vente
Vores arbejde er ikke færdiggjort. Med DNA-matchning er altid mere at arbejde på, og det bliver løbende forbedret af os i fremtiden. Den voksende størrelse af vores DNA-database, samt den øgede tilknytning mellem DNA-sæt og familietræer, giver os flere muligheder for at optimere DNA-matchning algoritmerne, og vi har til hensigt at gøre dette regelmæssigt og forbedre nøjagtigheden yderligere.
Med hensyn til DNA-data der er uploadet fra andre tjenester, understøtter vi stadig ikke DNA-matchning for DNA-sæt der er baseret på Illumina GSA-chip. Disse omfatter sæt fra 23andMe (seneste V5 version) og Living DNA. Vi har støtte til DNA-data fra GSA-chips der arbejder i vores laboratorium; det fungerer ret godt, men stadig ikke perfekt, så vi besluttede at udelukke det fra denne udgivelse indtil det er perfekt. Dette vil blive tilføjet i de kommende måneder.
Etnicitetsskøn er adskilt fra DNA-matchning, og de beskrevne forbedringer påvirker ikke etnicitetsestimaterne. Vi planlægger en opdatering til vores etnicitetsrapporter i de kommende måneder for også her at forbedre nøjagtigheden. Du kommer til at høre nærmere snart!
Næste skridt
Hvis du ikke allerede har gjort det, kan du bestille et MyHeritage DNA-sæt her for at få gavn af disse nye funktioner og forbedringer. Hvis du allerede har testet dig selv, kan du overveje skaffe DNA-sæt til nogle af dine slægtninge, især ældre familiemedlemmer, for at finde flere pårørende og triangulere dine egne matches. For eksempel kan du ved at teste en fætter til din mor eller far, vil enhver match med nye familiemedlemmer som du allerede har, og som også deles med den fætter, trianguleres til en fælles forfader, gennem en sti til en nyere forfader i dit stamtræ du deler med den fætter. Den nye kromosombrowser vil være til nytte for at forstå disse matches. Så hvis der er en bestemt gren i dit slægtstræ, som du er mest interesseret i at udforske yderligere, vil det være en idé at købe yderligere DNA-sæt til ældre familiemedlemmer i den gren.
Hvis du allerede har testet dit DNA andetsteds, kan du uploade dine DNA-data til MyHeritage. MyHeritage er den eneste af de tre største DNA-tjenester, der understøtter DNA-data upload. Udnyt dette mens det stadig er gratis og få gratis DNA-matches og gratis Etnicitetsskøn for dine eksisterende data. Med MyHeritages omfattende DNA-database på mere end en million mennesker, hvoraf de fleste kun testes hos MyHeritage, er dette en unik mulighed. Du får dine resultater gratis inden for 1-2 dage eller før.
Hvis du allerede administrerer mere end et DNA-sæt hos MyHeritage, bør du tage dig tid til at kontrollere, at hvert sæt du administrerer er forbundet med den rigtige person. Dette kan løses hvis det er nødvendigt, ved hjælp af siden “Administrer DNA-sæt”, der er tilgængeligt fra DNA-menuen.
Sidst men ikke mindst, er DNA-sæt hos MyHeritage meget mere nyttige når der er et slægtstræ forbundet med dem. Dette giver dig mulighed for at få bedre indsigt i dine DNA-matches, for eksempel ved tilstedeværelsen af Smart Matches, delte slægtsefternavne, eller delte forfædres fødested mellem dig og enhver DNA-match. Hvis du har et DNA-sæt hos MyHeritage, men intet stamtræ eller et meget lille stamtræ, er nu et godt tidspunkt at oprette et stamtræ eller forbedre dit eksisterende stamtræ. Det vil gavne dine DNA-matches, men primært vil det gavne dig selv.
God fornøjelse,
The MyHeritage Team